Service Discovery
Dubbo provides a Client-Based service discovery mechanism that relies on third-party registry center components to coordinate the service discovery process. It supports common registry centers such as Nacos, Consul, Zookeeper, etc.
Below is a basic working principle diagram of Dubbo’s service discovery mechanism:
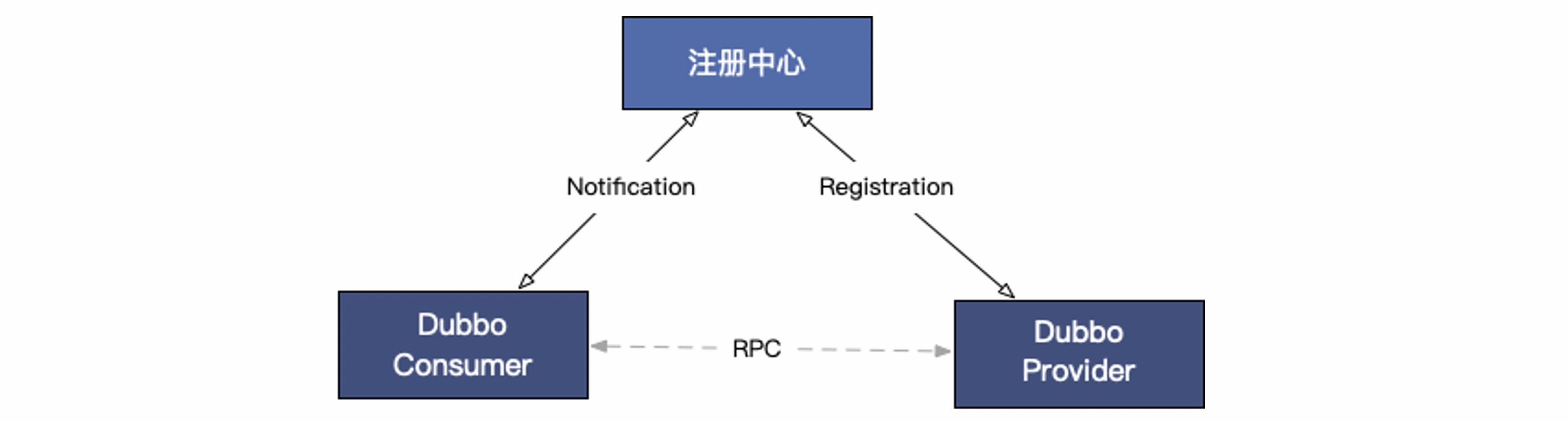
Service discovery involves three roles: provider, consumer, and registry center. Dubbo provider instances register URL addresses to the registry center, which aggregates the data. Dubbo consumers read the address list from the registry center and subscribe to changes. Whenever the address list changes, the registry center notifies all subscribed consumer instances with the latest list.
Service Discovery Mechanism for Million-Instance Clusters
Unlike many other microservice frameworks, Dubbo3’s service discovery mechanism was born out of Alibaba’s large-scale microservice e-commerce cluster practice scenarios. Therefore, its performance, scalability, and ease of use are significantly ahead of most mainstream open-source products in the industry. It is the best choice for enterprises to build scalable microservice clusters for the future.
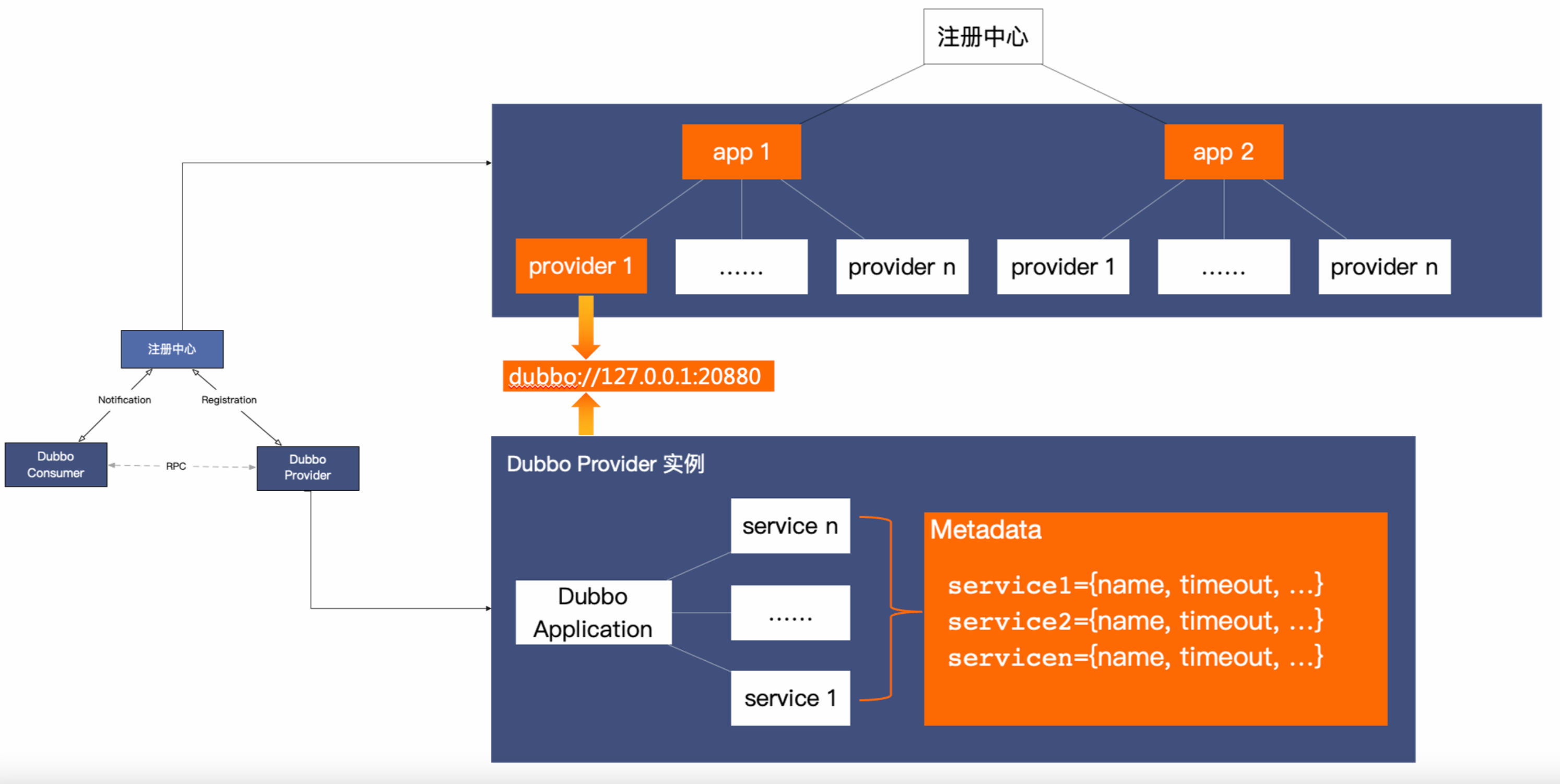
- Firstly, the Dubbo registry center aggregates instance data at the application granularity, and consumers subscribe precisely according to their consumption needs, avoiding the performance bottlenecks caused by full subscriptions in most open-source frameworks like Istio, Spring Cloud, etc.
- Secondly, the Dubbo SDK has made numerous optimizations in the process of handling the address list on the consumer side. Address notifications have been optimized with asynchronous, caching, bitmap, and other parsing optimizations, avoiding resource fluctuations in the consumer process that often occur with address updates.
- Finally, in terms of functionality richness and ease of use, besides synchronizing basic endpoint information like ip and port to consumers, Dubbo also synchronizes the metadata information of RPC/HTTP services and their configurations from the server side to the consumer side. This enables more granular collaboration between consumers and providers, and Dubbo provides many differentiated governance capabilities based on this mechanism.
Efficient Address Push Implementation
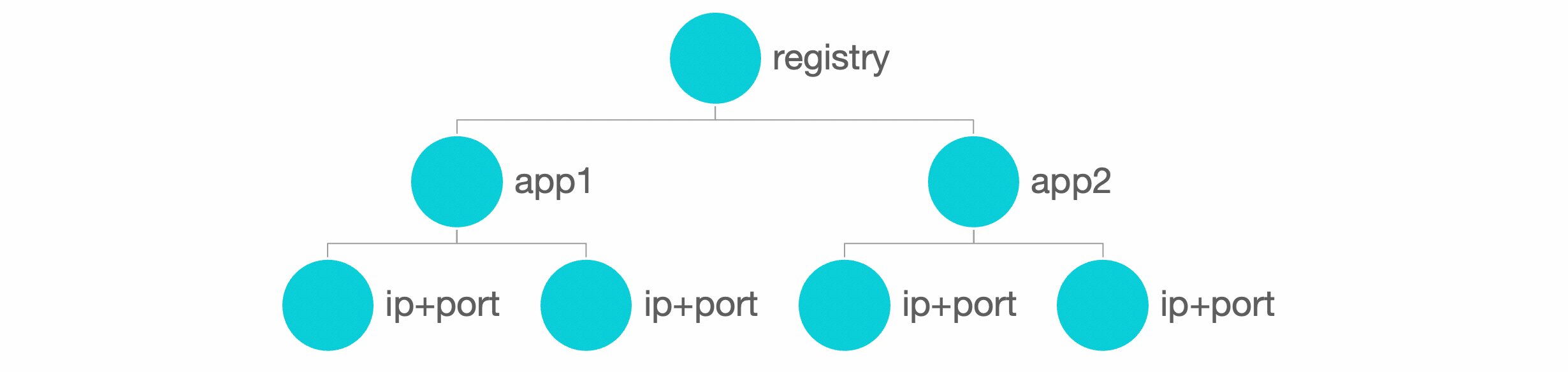
From the registry center’s perspective, it aggregates instance addresses for the entire cluster by application name (dubbo.application.name). Each service-providing instance registers its application name, instance ip:port address information (usually with a small amount of instance metadata, such as the machine’s region, environment, etc.) to the registry center.
In Dubbo2, the registry center aggregates instance addresses at the service granularity, which is finer than the application granularity, meaning more data is transmitted. Therefore, some performance issues were encountered in large-scale clusters. To address the inconsistency between Dubbo2 and Dubbo3 cross-version data models, Dubbo3 provides a smooth migration solution, ensuring that model changes are transparent to users.
Each consumer service instance subscribes to the instance address list from the registry center. Compared to some products that directly load the full data (application + instance address) from the registry center into the local process, Dubbo implements precise address information subscription as needed. For example, if a consumer application depends on app1 and app2, it will only subscribe to address list updates for app1 and app2, significantly reducing the burden of redundant data push and parsing.
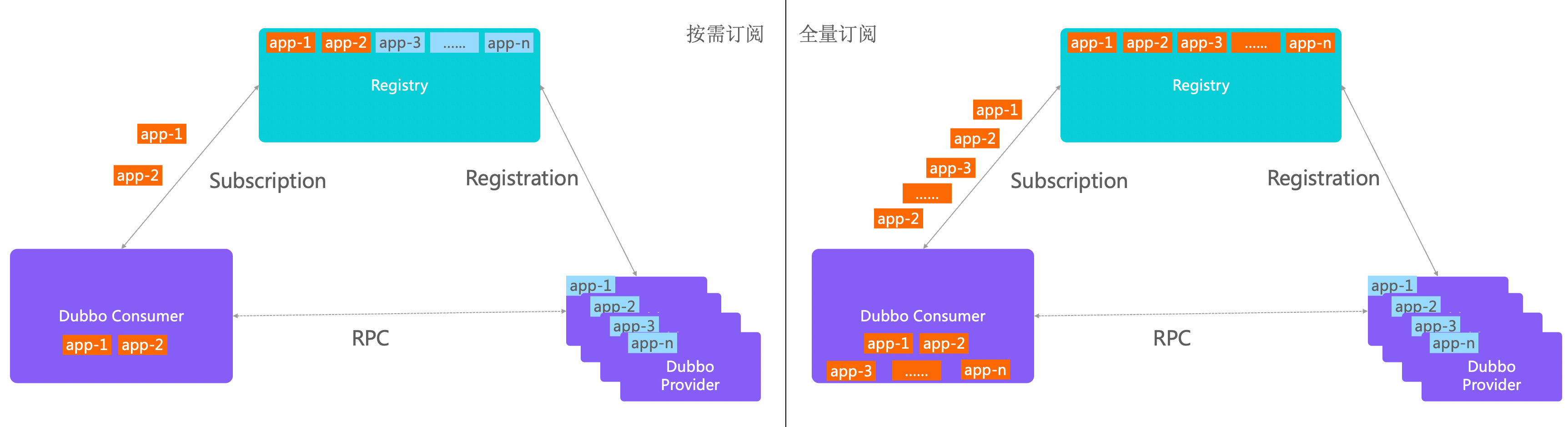
Rich Metadata Configuration
In addition to interacting with the registry center, Dubbo3’s complete address discovery process has an additional metadata channel, which we call the MetadataService. Instance addresses and metadata together form the effective address list on the consumer side.
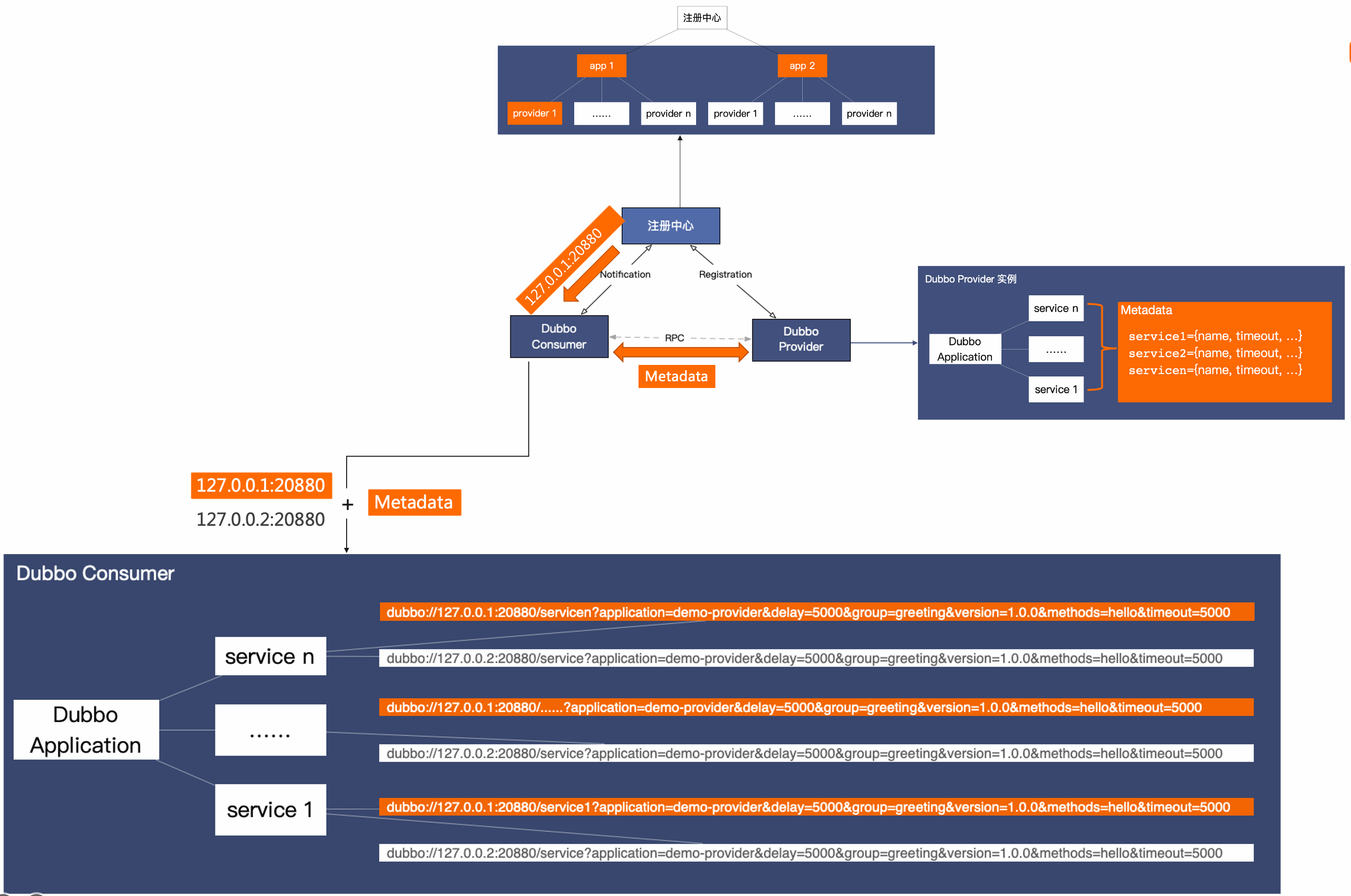
The complete workflow is shown in the figure above. First, the consumer receives the address (ip:port) information from the registry, then establishes a connection with the provider and reads the metadata configuration information of the peer through the metadata service. The two pieces of information are combined to form an effective service-oriented address list for the Dubbo consumer. These two steps occur before the actual RPC service call happens.
For the definition of MetadataService and a complete analysis of the service discovery process, please refer to Detailed Explanation of Application-Level Service Discovery.
For data synchronization in the service discovery model between microservices, REST has defined a very interesting maturity model. Interested readers can refer to this link https://www.martinfowler.com/articles/richardsonMaturityModel.html. According to the 4-level maturity definition in the article, Dubbo’s current interface-granularity model corresponds to the highest L4 level.
Configuration Method
Dubbo service discovery extends support for multiple registry components such as Nacos, Zookeeper, Consul, Redis, Kubernetes, etc. You can switch between different implementations through configuration, and it also supports configurations like authentication and namespace isolation. For specific configuration methods, please refer to the SDK documentation:
Dubbo also supports scenarios where multiple registries are configured within an application, such as dual registration and dual subscription. This is very useful for scenarios like intercommunication of different cluster addresses and cluster migration. We will add examples of Best Practices for this part in future documentation.
Custom Extension
Registry adaptation supports custom extension implementations. For details, please refer to Dubbo Extensibility