Dubbo3 Application-level Service Discovery Design
Objective
- Significantly reduce the resource consumption during the service discovery process, including improving the capacity limits of the registry center and reducing the resource consumption of address resolution on the consumer side, enabling the Dubbo3 framework to support service governance for larger cluster scales and achieving infinite horizontal scaling.
- Adapt to lower-level infrastructure service discovery models, such as Kubernetes and Service Mesh.
Background
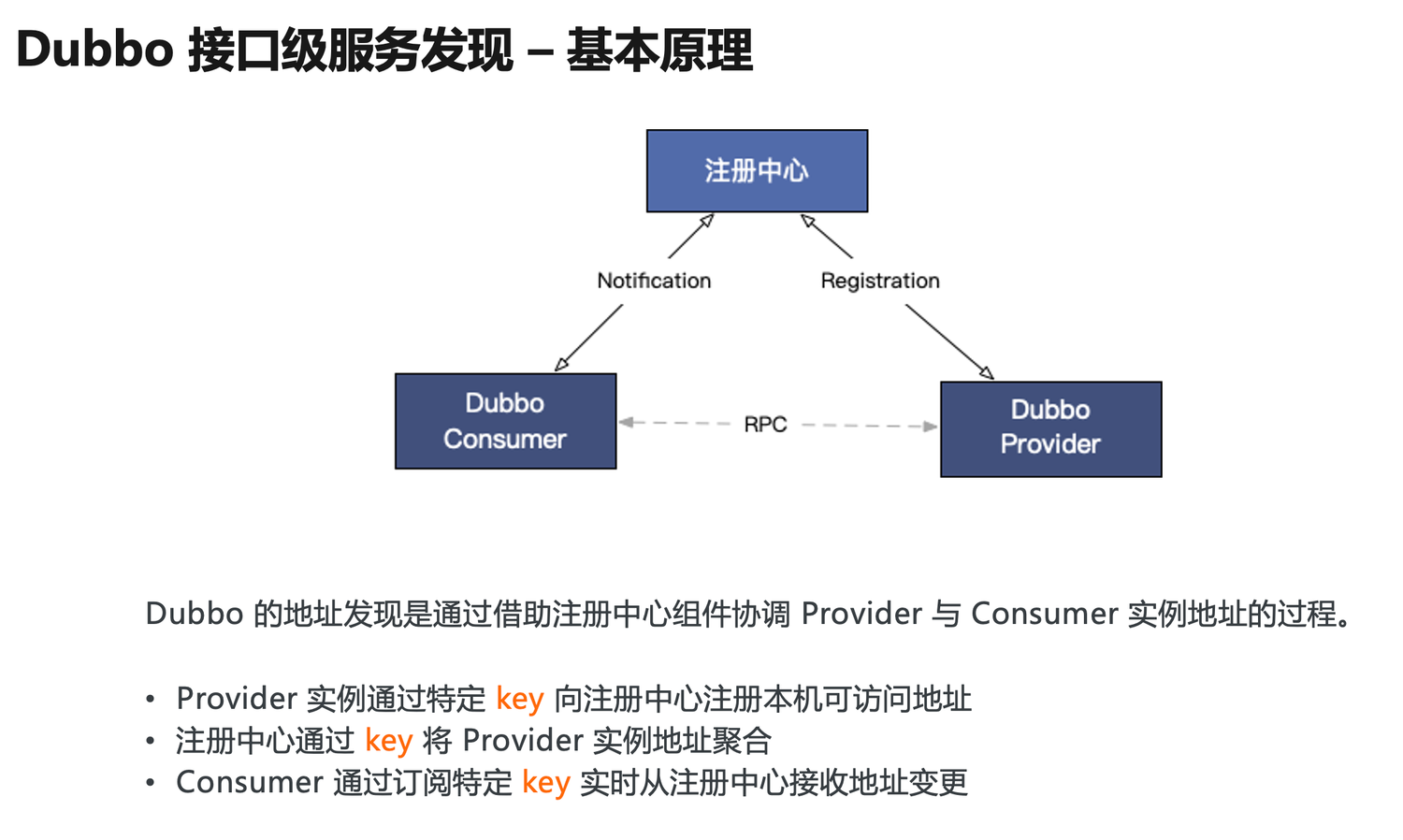
Let’s start with the classic working principle diagram of Dubbo. Since its inception, Dubbo has built-in capabilities for service address discovery. The provider registers its address to the registry center, and the consumer subscribes to receive real-time address updates from the registry center. Upon receiving the address list, the consumer initiates RPC calls to the provider based on specific load balancing strategies.
In this process:
- Each provider registers its accessible addresses with the registry using specific keys;
- The registry aggregates the provider instance addresses using this key;
- The consumer subscribes from the registry using the same key to receive the aggregated address list in a timely manner;
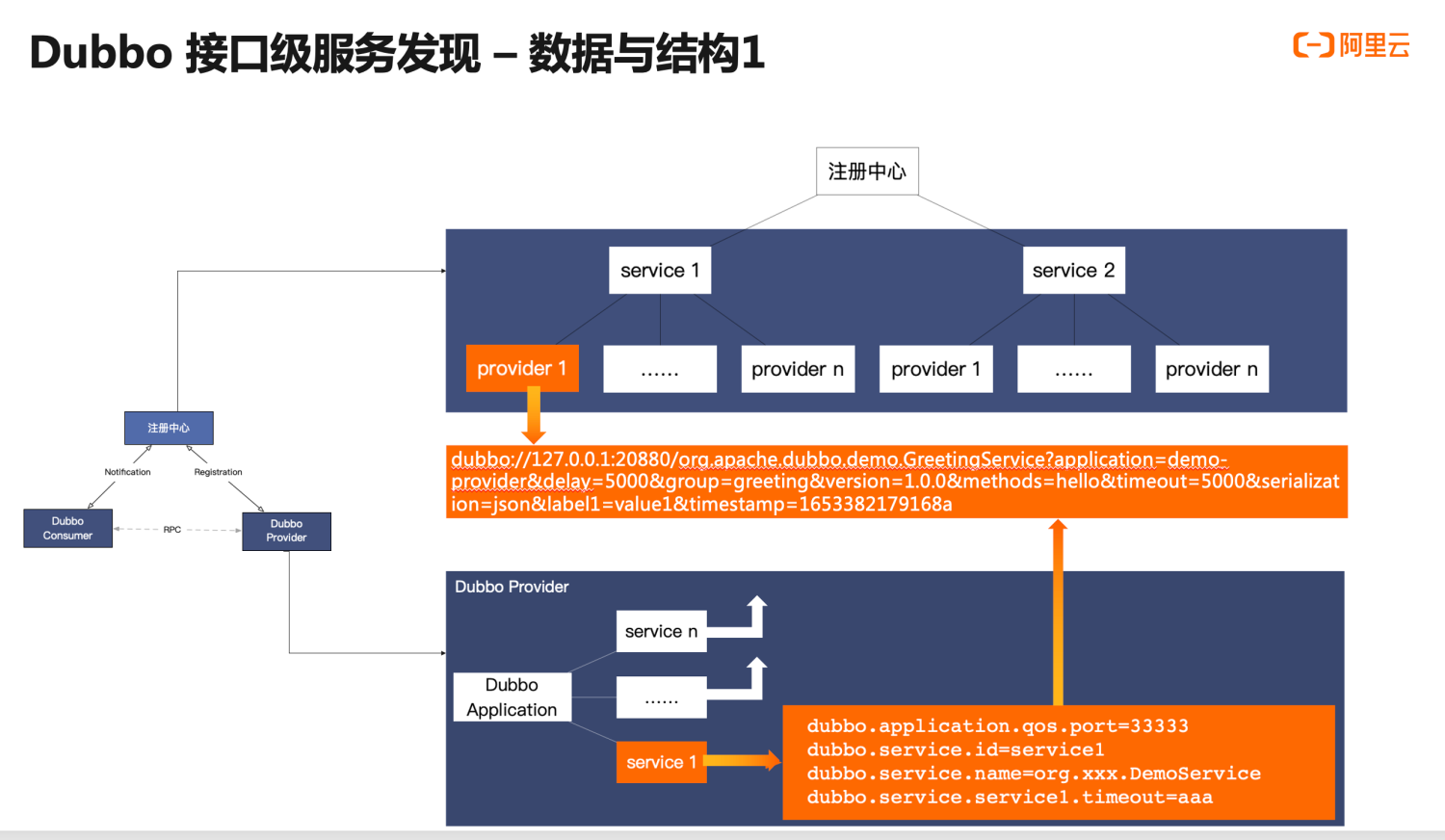
Here, we conduct a detailed analysis of the internal data structure of interface-level address discovery.
First, let’s look at the data and behavior of provider instances in the lower right corner. Typically, an application deployed as a provider will have multiple services, which are equivalent to services in Dubbo2. Each service may have its unique configurations. The process we discuss about service publishing is essentially the process of generating address URLs based on these service configurations, as depicted in the generated address data. Similarly, other services will also generate addresses.
Next, let’s examine the address data storage structure of the registry. The registry uses the service name for data partitioning, aggregating all address data under a service as child nodes, where the contents of the child nodes are the actual accessible IP addresses, which are the URLs in Dubbo, formatted as generated by the provider instance.

Here, the URL address data is divided into several parts:
- First, the instance accessible address, which mainly contains the IP and port information and is used by the consumer to generate TCP network connections for further RPC data transmission.
- Second, the RPC metadata, which is used to define and describe a single RPC request, indicating that this address data is related to a specific RPC service, its version number, group, and method-related information.
- The third part is RPC configuration data, where some configurations control the behavior of RPC calls, and others synchronize the state of the provider process instance, such as timeout and data encoding serialization method.
- The last part is custom metadata, which differs from the predefined configurations and allows users to expand and add custom metadata freely to enrich instance states further.
Combining the analysis above of Dubbo2’s interface-level address model with the initial basic principle diagram of Dubbo, we can draw several conclusions:
- First, the key for address discovery aggregation is the RPC granularity of the service.
- Second, the data synchronized by the registry center contains not only addresses but also various metadata and configurations.
- Thanks to 1 and 2, Dubbo achieves service governance capabilities at the application, RPC service, and method granularity.
This is the true reason why Dubbo2 has always been superior to many service frameworks in usability, service governance functionality, and scalability.
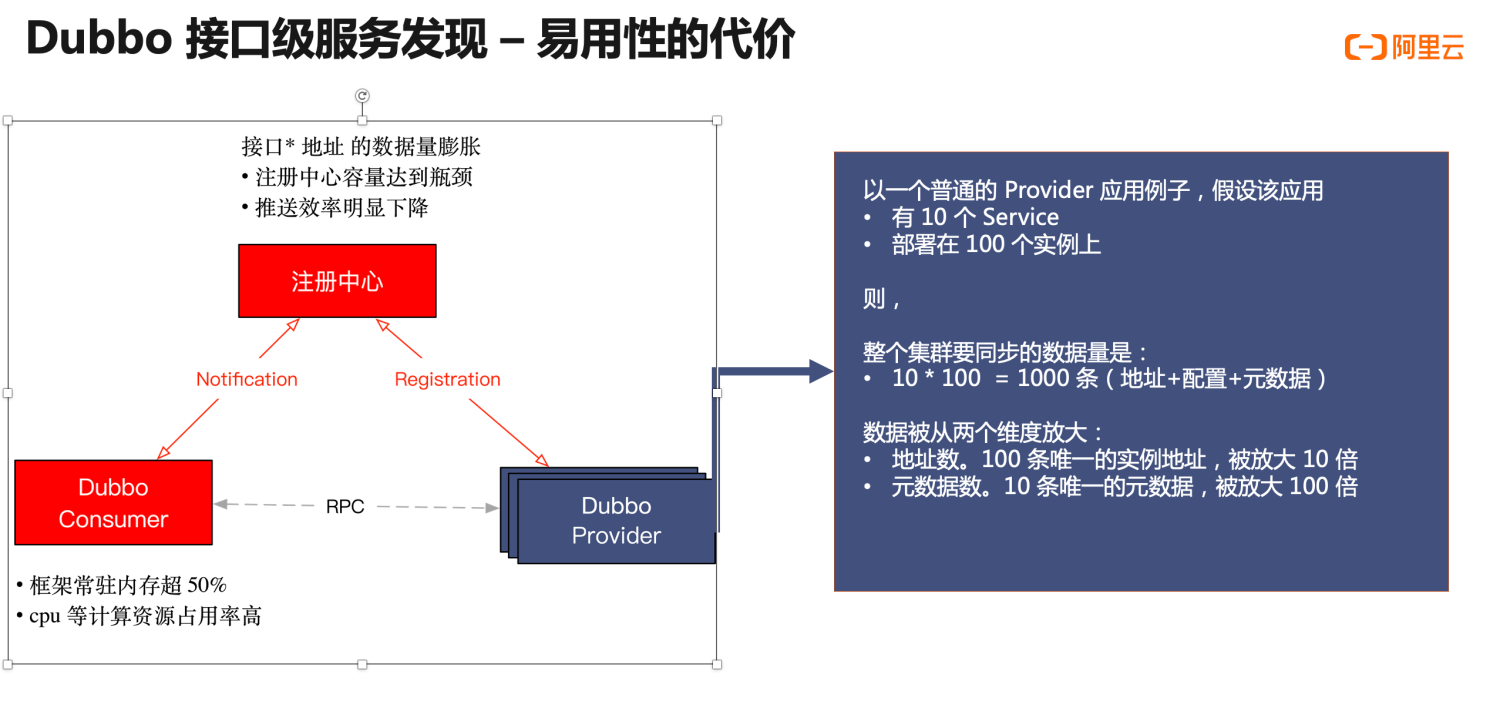
Every entity has its duality. While Dubbo2’s address model brings usability and powerful functionality, it also imposes some limitations on the horizontal scalability of the entire architecture. This issue is not perceivable under a typical-scale microservice cluster. However, as the cluster scales up and the total number of applications and machines reaches a certain level, each component within the cluster starts to encounter scaling bottlenecks. After summarizing the characteristics of multiple typical users such as Alibaba and ICBC in the production environment, we identified the following two prominent problems (highlighted in red in the diagram):
- First, the cluster capacity of the registry center reaches its upper limit. As all URL address data is sent to the registry center, its storage capacity reaches a limit, and the push efficiency declines as well.
- On the consumer side, the Dubbo2 framework’s memory resident usage has exceeded 40%, and the CPU and other resource consumption rates brought by each address push are also very high, affecting normal business calls.
Why does this issue arise? Let’s explore a specific provider example to illustrate why applications under the interface-level address model are prone to capacity issues. In the cyan area, let’s assume there is a typical Dubbo provider application with 10 RPC services defined internally and deployed on 100 machine instances. This application will generate data in the cluster totaling “number of services * number of machine instances,” which is 10 * 100 = 1000 entries. Data is magnified from two dimensions:
- From the address perspective. 100 unique instance addresses magnified by 10 times.
- From the service perspective. 10 unique service metadata entries magnified by 100 times.
Proposal
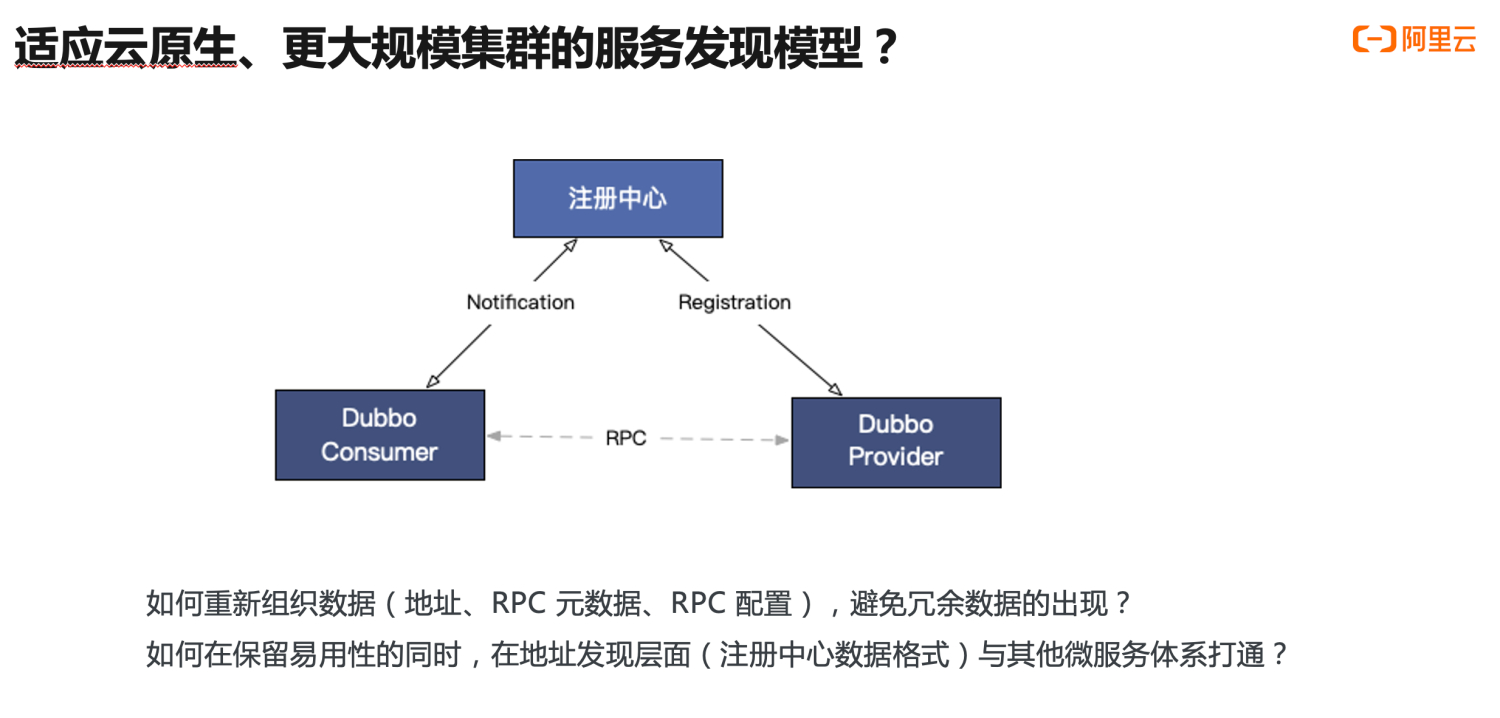
In response to this issue, under the Dubbo3 architecture, we must rethink two questions:
- How can we reorganize URL address data while retaining usability and functionality to avoid data redundancy, enabling Dubbo3 to support larger scale cluster horizontal expansion?
- How can we integrate service discovery with other microservice systems like Kubernetes and Spring Cloud?

The design of Dubbo3’s application-level service discovery solution fundamentally revolves around these two questions. The basic idea is: the aggregation elements in the address discovery link, which we previously mentioned as keys, are adjusted from service to application, hence the name application-level service discovery; additionally, the data content synchronized from the registry has been substantially simplified, keeping only the core IP and port address data.
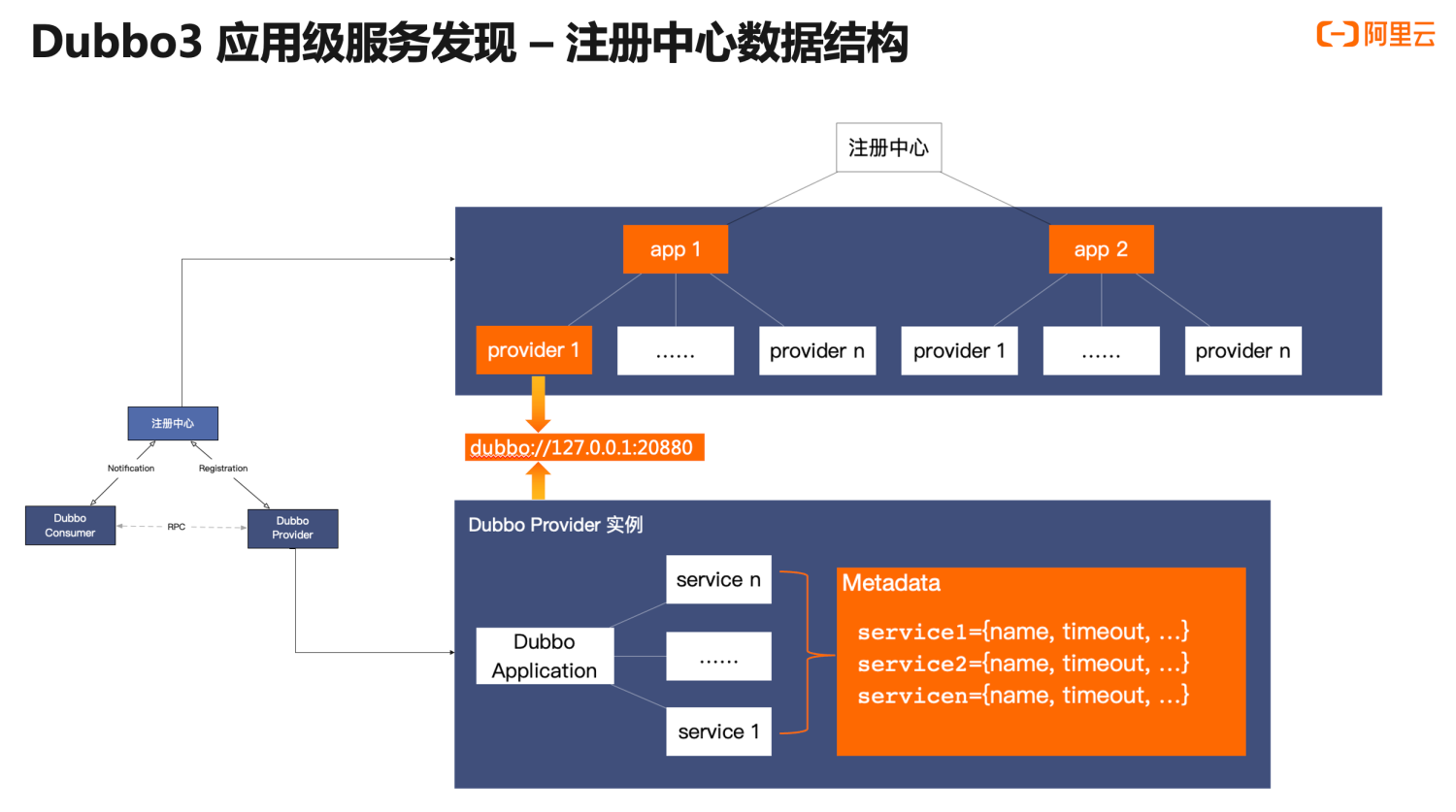
This is a detailed analysis of the internal data structure of the upgraded application-level address discovery. Comparing with the previous interface-level address discovery model, we primarily focus on the changes in the orange part. First, on the provider instance side, compared to registering one address data for each RPC service previously, a provider instance will only register one address with the registry center; on the registry center side, addresses are aggregated based on application names, with streamlined provider instance addresses under the application name node;

The above adjustments in application-level service discovery achieved a reduction in both the size of individual address data and the total number of entries while also introducing new challenges: we previously emphasized usability and functionality in Dubbo2 have been lost because metadata transmission has been streamlined. How to finely control the behavior of a single service becomes unachievable.
To address this issue, Dubbo3’s solution is to introduce a built-in MetadataService for metadata management, shifting from centralized push to point-to-point pull from the consumer to the provider. In this mode, the amount of metadata transmitted will no longer be an issue, thus allowing for more parameters to be extended and more governance data to be exposed within the metadata.
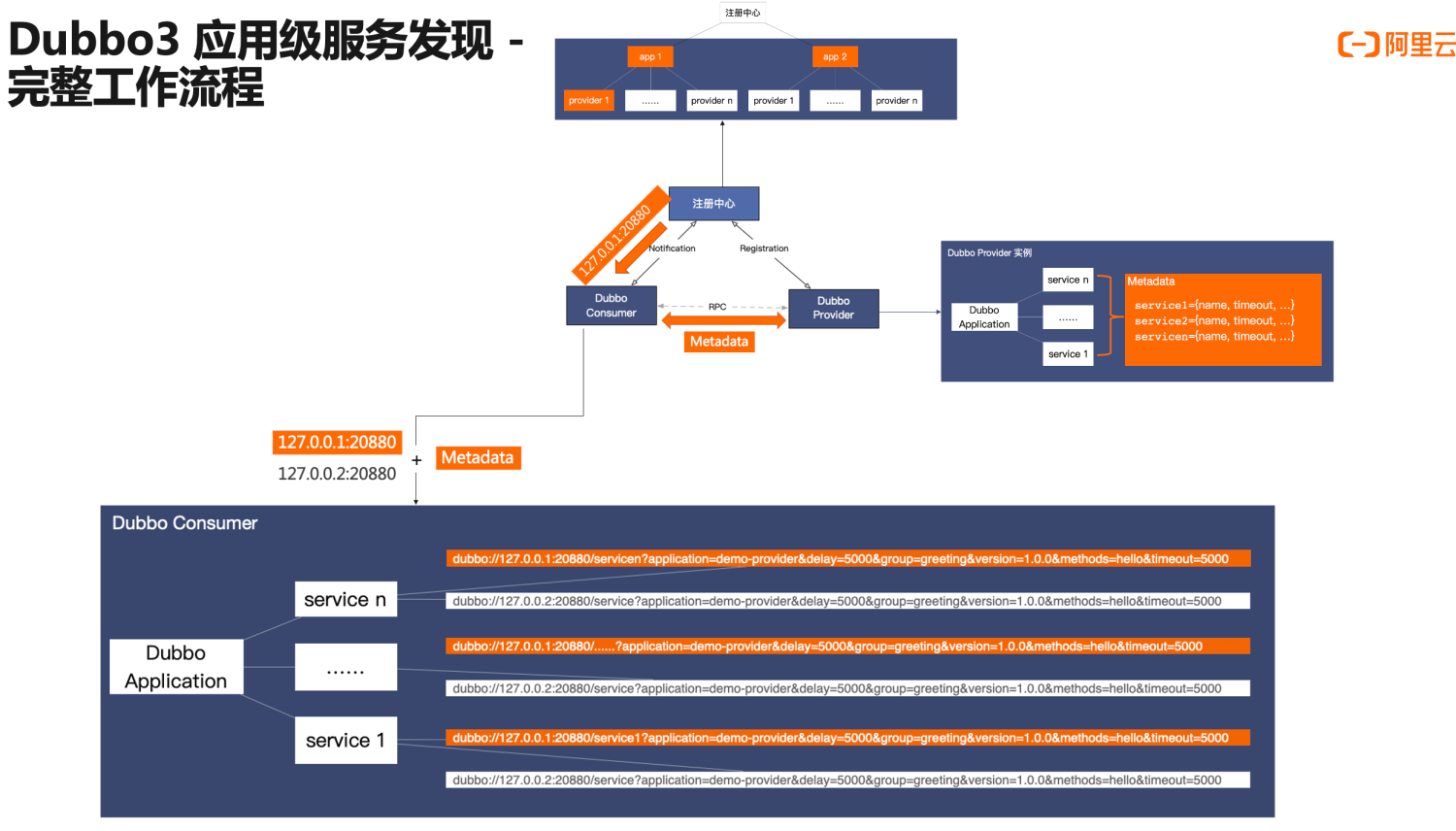
Here we focus on the address subscription behavior of the consumer. The consumer reads address data in two steps: first receiving the streamlined address from the registry center, and then calling the MetadataService to read the metadata information from the opposite end. After receiving these two data parts, the consumer will complete address data aggregation, ultimately restoring it to a URL address format similar to Dubbo2 in runtime. Therefore, from the final result, the application-level address model balances performance at the address transmission layer with functionality at the runtime layer.
This concludes the content regarding the background and working principles of application-level service discovery. Next, we will look into the process of Ele.me upgrading to Dubbo3, especially the transition to application-level service discovery.