This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Advanced cloud native - Dubbo 3.2 officially released
Background introduction
Apache Dubbo is an RPC service development framework, which is used to solve service governance and communication problems under the microservice architecture. It officially provides multi-language SDK implementations such as Java and Golang. The microservices developed using Dubbo are natively capable of remote address discovery and communication with each other. Using the rich service governance features provided by Dubbo, service governance demands such as service discovery, load balancing, and traffic scheduling can be realized. Dubbo is designed to be highly scalable, and users can easily implement various custom logics for traffic interception and location selection.
Rest protocol support
1. Why Rest?
With the popularization of mobile Internet, more and more applications need to be integrated with different systems. And these systems may use different communication protocols, which requires the application program to be able to flexibly adapt to various protocols. The Rest protocol is a very flexible protocol that communicates using HTTP and can be integrated with almost any system.
In the past, RPC frameworks typically communicated using a binary protocol, which was very efficient but not flexible enough. In contrast, the Rest protocol uses HTTP for communication, which is more convenient to integrate with other systems, and also easier to integrate with modern web and mobile applications.
Besides flexibility, the Rest protocol is also readable and easy to use. Using the Rest protocol, developers can test and debug services using common HTTP tools such as cURL or Postman, without the need for specific tools. Also, since the REST protocol uses standard HTTP methods such as GET, POST, PUT, and DELETE, it becomes easier for developers to understand and use the service.
2. How To?
In previous Dubbo versions, Rest protocol support was also provided, but there were the following problems:
Only supports JAX-RS annotation fields, which is more complex than the more widely adopted Spring Web annotations
It needs to rely on many external components, such as Resteasy, tomcat, jetty, etc., to work normally, which greatly increases the cost of use.
Therefore, in Dubbo version 3.2, we introduced the support of Spring Web annotation domain and the native support of Rest protocol without relying on any external components.
The most intuitive difference is that if you upgrade to Dubbo 3.2, services published through Spring Web can also be published directly through Dubbo. All you need to do is change the @Controller annotation to @DubboService annotation.
In addition, for users who originally used Spring Boot or Spring Cloud as a service split, they can also migrate smoothly to Dubbo based on this function, and obtain the powerful capabilities of Dubbo at a very low cost.
3. What’s next?
In the future, Dubbo will continue to improve. In addition to the existing features, we will also add the following new features to better meet the needs:
Native support for HTTP/2 and HTTP/3 protocols. This means that you can use Dubbo to communicate with other systems more easily without worrying about protocol compatibility.
Referring to Spring Web annotations, Dubbo natively provides support for Web annotations, so that users can get the same experience as using Spring Web without relying on Spring Web.
Support zero transformation of existing services and publish them with the Rest protocol. This feature allows you to manage your services more flexibly without making any changes to existing services. You can publish your services through the Rest protocol, so that your services can be used by other systems more easily.
Observable system
Under the microservice architecture, the business system is composed of more and more services, and the services call each other. The ensuing problem is how to quickly locate the fault and solve it in time. In order to solve this problem, we need more tools and techniques to ensure the reliability of the whole system. One of the solutions is to use logging and analytics so that you can better track how your application is doing, find potential problems and fix them in a timely manner. In addition, using visual monitoring tools can help us better understand the status of the entire system, so as to better predict and solve problems. Finally, we can also use automated testing to ensure the quality of each service, as well as the stability and reliability of the entire system, so as to better meet customer needs.
A complete observable system should include the following functions:
Metrics indicator monitoring, used to collect and analyze various indicator data, including system performance, resource consumption, etc. Through indicator monitoring, users can keep abreast of the operation of the system, find abnormalities and take corresponding measures.
Tracing Distributed tracing, used to trace the call links between various services in the system, to help users discover and locate potential performance problems, bottlenecks, etc. Through distributed tracing, users can deeply understand the operation process of the system, identify possible problems and make effective optimization and adjustment.
Logging log management, used to record various events and operations in the system, including error logs, access logs, transaction logs, etc. Through log management, users can learn about the running status of the system, fault information, etc., and help users quickly locate problems and handle them accordingly.
To sum up, the above three functions can not only help users quickly locate faults, improve system reliability and stability, but also help users deeply understand the operation and performance of the system, and provide users with comprehensive monitoring and protection.
In Dubbo version 3.2, we mainly enhanced Metrics and Tracing.
1. Metrics
In terms of metrics, we use Micrometer to greatly increase the buried points of indicators, including but not limited to core service indicators such as QPS, RT, total number of calls, number of successes, number of failures, and failure reason statistics. In order to better monitor the running status of services, Dubbo also provides monitoring of the status of core components, such as the number of thread pools, service health status, etc. In addition, Dubbo also supports the standard Prometheus Pull and Push modes, and provides several official native Grafana panels to achieve production-oriented Metrics all-weather observation.
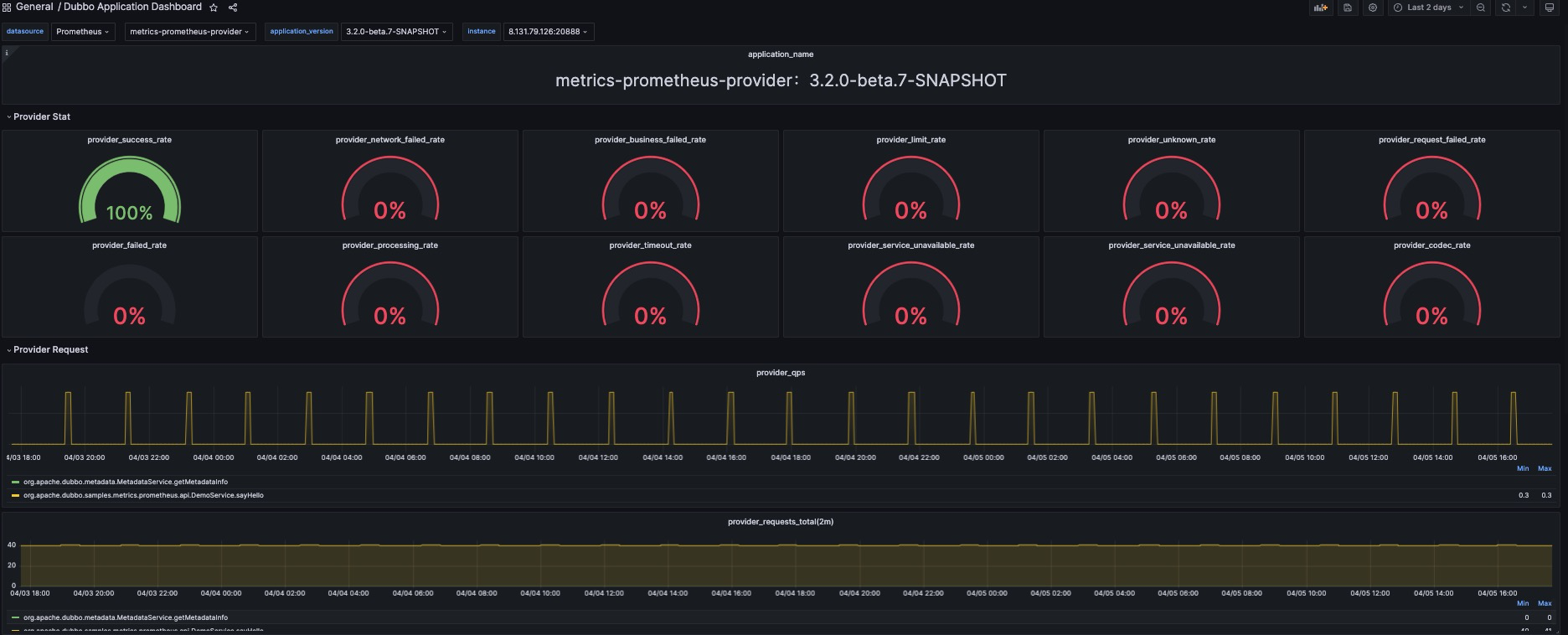
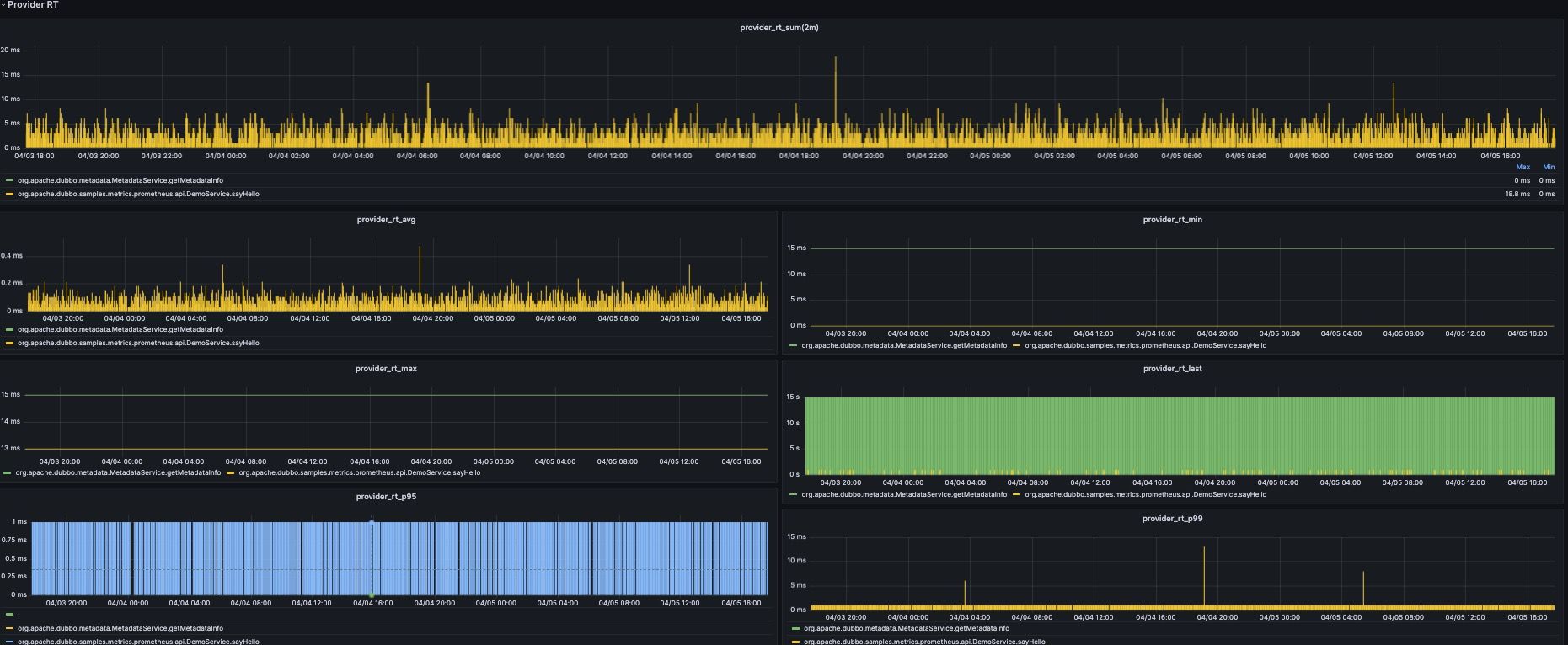
For all users, only need to upgrade to Dubbo 3.2 version and add dubbo-spring-boot-observability-starter dependency to get Metrics capability. After the application starts, relevant indicators will be exposed under the metrics command of Dubbo QoS, which can be obtained locally through http://127.0.0.1:22222/metrics. In addition, for users who use Spring Actuator, Dubbo will also expose these data by default.
Tracing
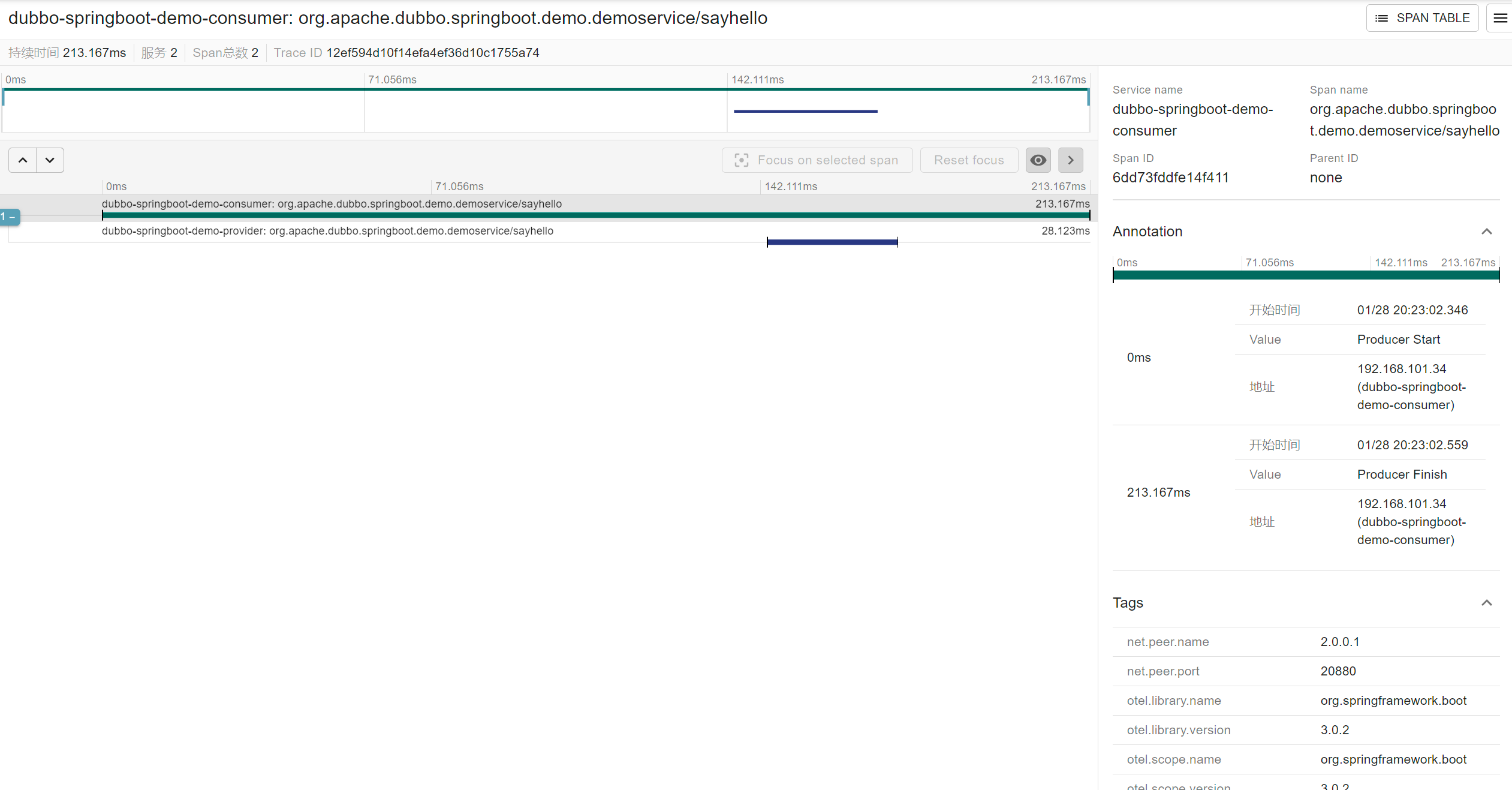
In terms of Tracing, we also implemented tracking of buried points during request runtime based on Micrometer. We implement this function natively through the Filter interceptor. We support exporting trace data to some mainstream implementations, such as Zipkin, Skywalking, Jaeger, etc. In this way, the analysis and visual display of the full link tracking data can be realized.
Logging
In addition, for Logging, Dubbo has introduced an error code mechanism since version 3.1, realizing full coverage of WARN and ERROR level logs. In abnormal scenarios, it supports quick indexing of official website resolution documents.
Native Image native support
In terms of Native Image, Dubbo will officially support Native Image based on GraalVM starting from 3.2. Starting from Dubbo3.0, Dubbo has already explored some Native Image support, but the ease of use and support are not ideal. From 3.2 Starting from version 1, Dubbo will simplify the way users access Native Image. It can be mainly divided into three aspects:
- Compile plugin configuration upgrade: from the original native-image-maven-plugin to dubbo-maven-plugin +native-maven-plugin, which distinguishes the native image configuration officially provided by Graalvm from the native image configuration required by Dubbo, simplifying The native image configuration that users need to care about
<plugin>
<groupId>org.graalvm.nativeimage</groupId>
<artifactId>native-image-maven-plugin</artifactId>
<version>21.0.0.2</version>
<executions>
<execution>
<goals>
<goal>native-image</goal>
</goals>
<phase>package</phase>
</execution>
</executions>
<configuration>
<skip>false</skip>
<imageName>demo-native-provider</imageName>
<mainClass>org.apache.dubbo.demo.graalvm.provider.Application</mainClass>
<buildArgs>
--no-fallback
--initialize-at-build-time=org.slf4j.MDC
--initialize-at-build-time=org.slf4j.LoggerFactory
--initialize-at-build-time=org.slf4j.impl.StaticLoggerBinder
--initialize-at-build-time=org.apache.log4j.helpers.Loader
--initialize-at-build-time=org.apache.log4j.Logger
--initialize-at-build-time=org.apache.log4j.helpers.LogLog
--initialize-at-build-time=org.apache.log4j.LogManager
--initialize-at-build-time=org.apache.log4j.spi.LoggingEvent
--initialize-at-build-time=org.slf4j.impl.Log4jLoggerFactory
--initialize-at-build-time=org.slf4j.impl.Log4jLoggerAdapter
--initialize-at-build-time=org.eclipse.collections.api.factory.Sets
--initialize-at-run-time=io.netty.channel.epoll.Epoll
--initialize-at-run-time=io.netty.channel.epoll.Native
--initialize-at-run-time=io.netty.channel.epoll.EpollEventLoop
--initialize-at-run-time=io.netty.channel.epoll.EpollEventArray
--initialize-at-run-time=io.netty.channel.DefaultFileRegion
--initialize-at-run-time=io.netty.channel.kqueue.KQueueEventArray
--initialize-at-run-time=io.netty.channel.kqueue.KQueueEventLoop
--initialize-at-run-time=io.netty.channel.kqueue.Native
--initialize-at-run-time=io.netty.channel.unix.Errors
--initialize-at-run-time=io.netty.channel.unix.IovArray
--initialize-at-run-time=io.netty.channel.unix.Limits
--initialize-at-run-time=io.netty.util.internal.logging.Log4JLogger
--initialize-at-run-time=io.netty.channel.unix.Socket
--initialize-at-run-time=io.netty.channel.ChannelHandlerMask
--report-unsupported-elements-at-runtime
--allow-incomplete-classpath
--enable-url-protocols=http
-H:+ReportExceptionStackTraces
</buildArgs>
</configuration>
</plugin>
becomes:
<plugin>
<groupId>org.graalvm.buildtools</groupId>
<artifactId>native-maven-plugin</artifactId>
<version>0.9.20</version>
<configuration>
<classesDirectory>${project.build.outputDirectory}</classesDirectory>
<metadataRepository>
<enabled>true</enabled>
</metadataRepository>
<requiredVersion>22.3</requiredVersion>
<mainClass>org.apache.dubbo.demo.graalvm.provider.Application</mainClass>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-maven-plugin</artifactId>
<version>${project.version}</version>
<configuration>
<mainClass>org.apache.dubbo.demo.graalvm.provider.Application</mainClass>
</configuration>
<executions>
<execution>
<phase>process-sources</phase>
<goals>
<goal>dubbo-process-aot</goal>
</goals>
</execution>
</executions>
</plugin>
- In the old version, users were required to manually generate and complete the unique Adaptive code in Dubbo. Users of the new version do not need to care about these details.
- The configuration file under META-INF.native-image generated by the Dubbo framework in the old version will be directly generated in the user’s project directory, and the new version 3.2 will be compiled into the target without affecting the user’s project structure. In addition, the Dubbo framework will no longer use the method of manually completing the native image, but will automatically detect and generate the required configuration files, which simplifies the experience of Dubbo developers. This can also reduce the size of the final compiled binary package and improve compilation speed.
In addition to improving ease of use, Dubbo will support API, annotations, and XML configuration methods in native image scenarios in version 3.2, and support compatibility with native in SpringBoot3.
other
JDK 17 & Spring Boot 3 native support
JDK 17 is the latest LTS version of Java after JDK 11, including many new features and improvements, such as Sealed classes, garbage collector improvements, and more.
Since JDK 16 began to restrict Java internal class reflection, Dubbo’s serialization and dynamic proxy have been affected to a certain extent. In Dubbo 3.2, we solved the compatibility problem from the bottom through the optimization of Fastjson2 and Javassist. At present, Dubbo can run perfectly on JDK17, and all unit tests and most integration tests have also been tested on the JDK 17 platform.
For the upcoming JDK 21 LTS, Dubbo is intensively adapting it. We will add support for JDK 21 and Dubbo coroutines (Project Loom) in version 3.3.
RPC performance greatly improved
In version 3.2, we have optimized the performance of RPC calls, and the optimized content is as follows.
Eliminates synchronization lock contention and blocking code (
triple)- When creating an HTTP/2 Stream Channel in version 3.1, the method of synchronously blocking user threads is used to wait for the Stream Channel to be created, and the remote call is initiated after the creation is completed. In 3.2, we will create the behavior of HTTP/2 Stream Channel
asynchronousand ensure that the request is initiated after the creation is completed, so as toreduce unnecessary waiting for user threads. - In version 3.1, there is a synchronization lock competition between the user thread and the Netty I/O thread. The IO thread will check the Socket availability for each write request, and the Socket availability check method is also used in the user thread, but the Socket availability in the JDK The implementation of the check uses
synchronizedto ensure concurrency safety. In order to reduce this part of the time-consuming, we remove the user thread check and eliminate this part of the time-consuming.
- When creating an HTTP/2 Stream Channel in version 3.1, the method of synchronously blocking user threads is used to wait for the Stream Channel to be created, and the remote call is initiated after the creation is completed. In 3.2, we will create the behavior of HTTP/2 Stream Channel
Reduced request response delay with synchronous blocking calls (
dubbo,triple)In the RPC call in SYNC mode in version 3.1, we use a blocking queue to wait for the response written back by the remote service. When the response is written back, it will be added to the queue and wake up the blocked user thread. In 3.2, we replaced the blocking queue with a concurrent queue, and used its CAS mechanism to greatly reduce the number of threads entering blocking, improve CPU utilization and reduce response processing delay
Reduced the number of thread switches (
triple)In version 3.1, the RPC call in SYNC mode uses a consumer thread pool for processing when receiving the response, and wakes up the user thread to receive the response after the processing is completed. However, through the analysis of the consumer thread pool in SYNC mode is unnecessary, an additional layer of consumer thread pool processing not only wastes server resources but also reduces performance, so we removed the consumer thread pool in SYNC mode in version 3.2 , the interaction model changed from
NettyEventLoop → ConsumerThread → UserThreadtoNettyEventLoop → UserThread, so as to reduce the waste of server resources and improve performanceOptimized I/O performance (
dubbo,triple)In version 3.1, we used the Netty framework to achieve network communication, but every time we wrote a message to the peer, we directly flashed it to the peer, resulting in a very high number of system calls and reducing the communication performance. For this reason, we have optimized it in version 3.2. Every time a message is sent, the message is first submitted to a write queue, and multiple messages are written out at the right time, thereby improving I/O Utilization rate greatly improves RPC communication performance.
Support serialization of messages on user threads (
dubbo,triple)In version 3.1, the deserialization of messages in RPC communication is performed in a single I/O thread, which makes it impossible to take advantage of the advantages of multi-core CPUs. For this reason, in version 3.2, we support time-consuming tasks such as deserialization on user threads, and evenly distribute the pressure of I/O threads to multiple CPU cores, thereby improving the performance of large packets. `Scenario RPC performance.
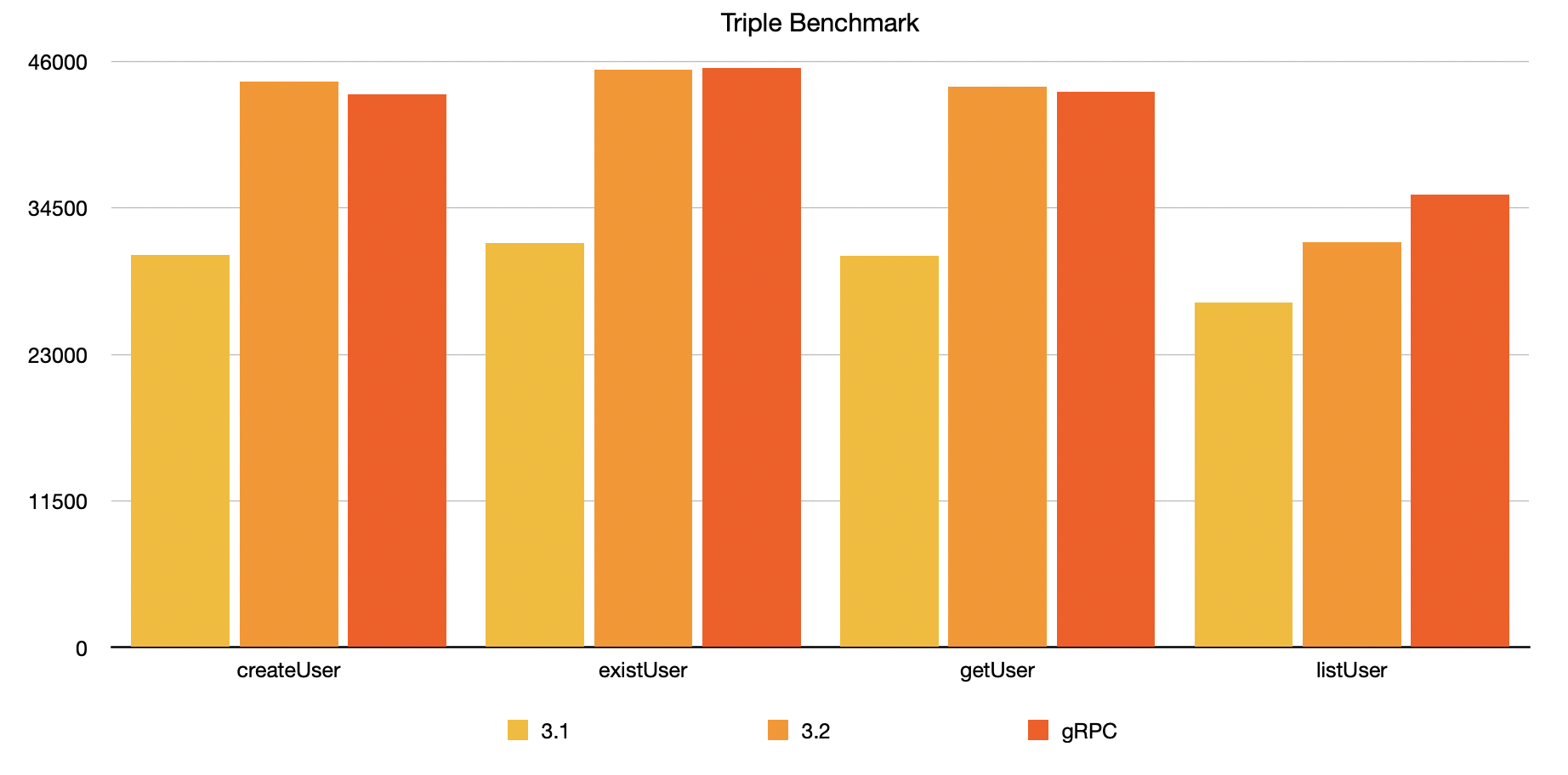
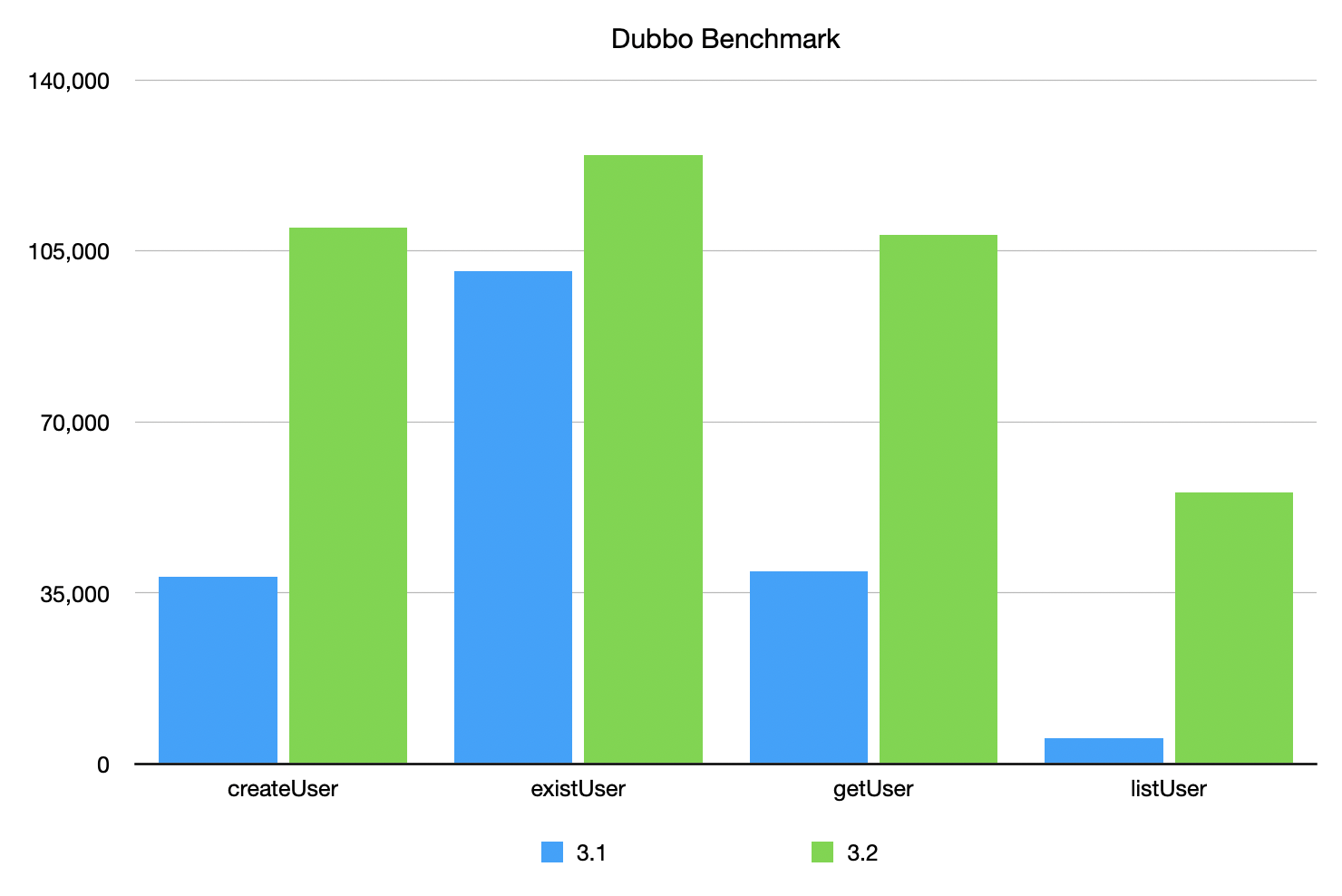
The performance improvement of 3.2 compared with 3.1 is as follows:
Triple protocol: In the scenarios of createUser, existUser, and getUser with small packets, the improvement rate is about 40-45%, and the improved performance is basically the same as that of gRPC in the same scenario. The increase of about 17% in the large message scenario listUser, compared to 11% lower than that of gRPC in the same scenario.
Dubbo protocol: The improvement rate is about 180% in the case of createUser and getUser in small message scenarios. The improvement rate of the very small message existUser (only one boolean value) is about 24%, while the improvement rate of the larger message listUser is the highest, reaching 1000%!
How to upgrade to Dubbo 3.2
Pom upgrade
The latest Dubbo Maven coordinates are:
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>3.2.0</version>
</dependency>
Compatibility
For the vast majority of users, upgrading to Dubbo 3.2.0 is completely smooth, and only needs to modify the version of the dependent package.
Enhancement of serialization verification logic (important)
As mentioned above, in Dubbo 3.2.0 version, Dubbo will enable the strong verification of the serialization whitelist by default to improve the security of Dubbo and avoid the problem of remote command execution. The current mechanism automatically trusts some classes through the package name recursive mechanism, but for some users who use generics and may have incomplete scanning, we recommend that you upgrade to Dubbo 3.1.9 or add
-Ddubbo.application.serialize- check-status=WARNconfiguration. After observing for a period of time (via logs and QoS commands), if no security alarm is triggered, you can configure the strong check mode.For the configuration of custom whitelist, please refer to
Documentation/SDK Manual/Java SDK/Advanced Features and Usage/Improve Security/Class Inspection Mechanismon the official website for configuration.Modification of default serialization
Starting from version 3.2.0 of Dubbo, the default serialization method is switched from
hessian2tofastjson2. For applications upgraded to 3.2.0, Dubbo will automatically try to usefastjson2for serialization. Please note that whether it is the client or the server, as long as one end has not been upgraded to 3.2.0, it will be downgraded tohessian2serialization to ensure compatibility.Push short protection is disabled by default
The purpose of push empty protection is that when the registration center fails and actively pushes empty addresses, Dubbo keeps the last batch of provider information to ensure service availability. However, in most cases, even if the registry fails, empty addresses will not be pushed, only in some special cases. If push short protection is turned on, it will have a greater impact on Dubbo’s Fallback logic, heartbeat logic, etc., and bring troubles to developers when using Dubbo.
If you need to enable empty protection in the production environment to achieve high availability, you can configure
dubbo.application.enable-empty-protectiontotrue. However, please note that it is known that turning on the push protection will cause the server application to roll back to the original version after upgrading from2.6.xand2.7.xversions that only support interface-level service discovery to3.xAn exception occurs, which may cause the service call to fail in extreme cases.
Summarize
Dubbo 3.2 is a very important version, it brings many new features and improvements, making Dubbo more powerful and easy to use. We are very grateful for the support and contributions of the community, and hope that everyone can experience Dubbo 3.2 as soon as possible and enjoy the convenience and advantages it brings.